强化学习基本概念
0.综述类网站与文章
Spinning Up as a Deep RL Researcher
A (Long) Peek into Reinforcement Learning
1. Key Concepts
environment 环境
model 描述环境如何对特定动作做出反应(control里面的传函和状态传递方程)
states 一般写作 s
actions 一般写作 a
reward 环境会提供奖励 (r∈R) 作为反馈。
P transition probabilities between states
agent 智能体,与环境交互并进行控制的主体
policy 一般写作π(s), 告诉我们在状态 s 中要采取什么行动。它是从状态 s 到作 a 的映射,可以是确定性的,也可以是随机的,目的是最大化总奖励,也就是下面说的value.
策略本质上是一个概率分布,πθ(a∣s)\pi_\theta(a | s)πθ(a∣s) 直接给出了每个动作的概率
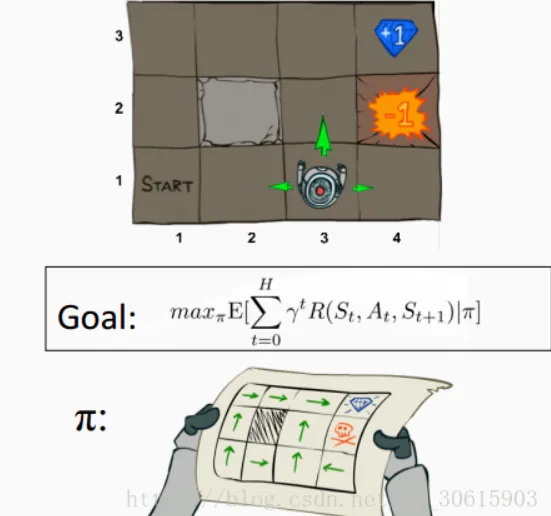
value 目标指标,量化了一个 policy 的好坏, control 里的代价函数可以算是一种 value

episode 在agent和环境交互中不断积累关于环境的知识,学习最佳策略。系统的变化过程构成一个交互序列,或者叫trial 、trajectory
transition probability function 转移概率函数 P & reward function 奖励函数 R

action-value Q 值
可以把 Q(s,a)Q(s, a)Q(s,a) 理解为:
处于某个状态 s 时,如果执行动作 a,那么未来能得到多少奖励;是对 “选择这个动作值得吗?” 这个问题的量化评估。

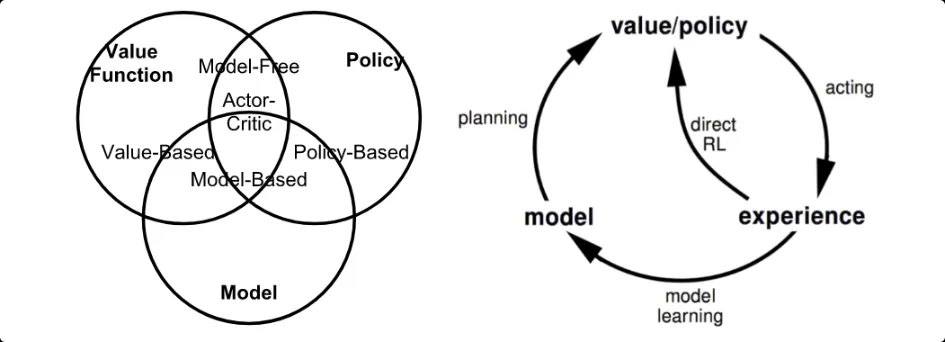
2. Basic Approaches
DP方法 Dynamic Approach 动态规划
模型完全已知时,按照 Bellman 方程,我们可以使用动态规划 (DP) 迭代评估价值函数并改进策略。
- 策略评估
- 策略改进
- 策略迭代 Generalized Policy Iteration (GPI) algorithm
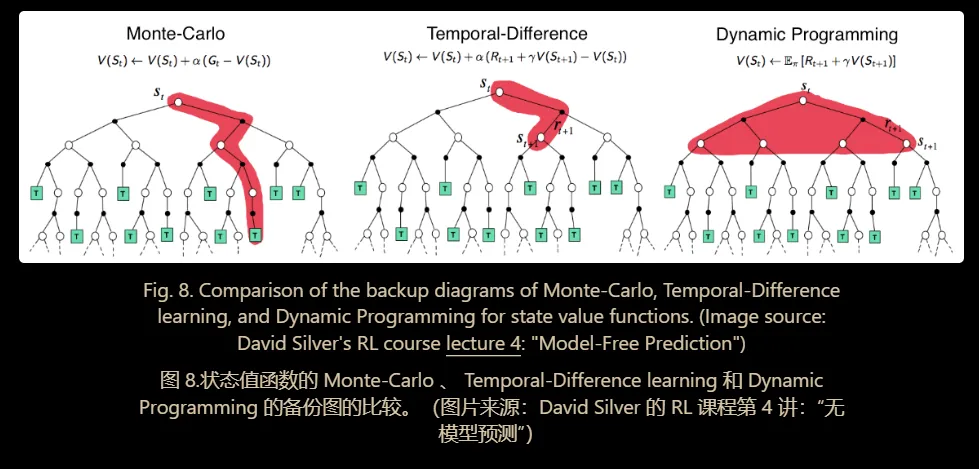
MC方法 Monte-Carlo Methods
蒙特卡洛 (MC) 方法使用一个简单的想法:它从原始经验中学习,而不对环境动态进行建模,并将观察到的平均回报计算为预期回报的近似值。
TD方法 Temporal-Difference Learning
无模型、从经验中学习
但是相较于MC方法不需要完整的 episode
TD 学习方法根据现有估计更新目标,而不是像 MC 方法那样完全依赖实际奖励和完整回报。这种方法称为 bootstrapping。

3. MDP过程
更正式地说,几乎所有的 RL 问题都可以被框定为马尔可夫决策过程 (MDP)。MDP 中的所有状态都具有 “Markov” 属性,指的是 future 只取决于当前状态,而不取决于历史的事实:
P[St+1|St]=P[St+1|S1,…,St]
或者换句话说,鉴于现在,未来和过去在条件上是独立的,因为当前状态封装了我们决定未来所需的所有统计数据。
马尔可夫定义过程由五个元素 M=⟨S,A,P,R,γ⟩ 组成,其中符号与上一节中的关键概念具有相同的含义,与 RL 问题设置非常一致
- 标题: 强化学习基本概念
- 作者: Porcovsky
- 创建于 : 2025-02-07 09:46:19
- 更新于 : 2025-06-11 21:30:00
- 链接: https://pocro.github.io/2025/02/07/强化学习基本概念/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。