
Q-learning
参考博客与论文
Q-Learning Algorithms: A Comprehensive Classification and Applications
1.基本概念
Q-learning 的核心是学习一个 Q 函数,该函数估计了在给定状态(State)下,采取某个动作(Action)所能获得的长期奖励的期望值。它的目标是找到一个最优策略,使得智能体在每个状态下都能选择最优动作,从而最大化累积的奖励。
Q 函数的定义如下:
Q(s,a)=当前状态 s 下,选择动作 a 所获得的长期回报
其中:
s是状态空间中的一个状态。
a是智能体在状态 s 下可以选择的动作。
Q(s,a)是智能体在状态 s 下采取动作 a 后,能够获得的期望奖励。

其中Rt+1是从 state St移动到 state St+1时收到的奖励,α是学习率 (0<α≤1)。
学习率α
决定了新获取的信息在多大程度上覆盖旧信息。
因子 0 使代理什么都学不到(专门利用先验知识),而因子 1 使代理只考虑最新的信息(忽略先验知识以探索可能性)。
在完全确定性 环境中,学习率 αt=1 是最优的。
当问题是随机 的时,算法在某些技术条件下收敛于学习率,这要求它减少到零。在实践中,通常使用恒定的学习率,例如 αt=0.1
衰减系数γ
决定了未来奖励的重要性。
系数为 0 将使代理仅考虑当前奖励(即rt)(在上面的更新规则中)而变得“短视”,而接近 1 的系数将使其争取长期的高奖励。如果折扣系数达到或超过 1,则作值可能会有所不同。
γ 越大,agent对未来越了解,反之γ越小,agent越“短视” ,对未来状态的预测减弱
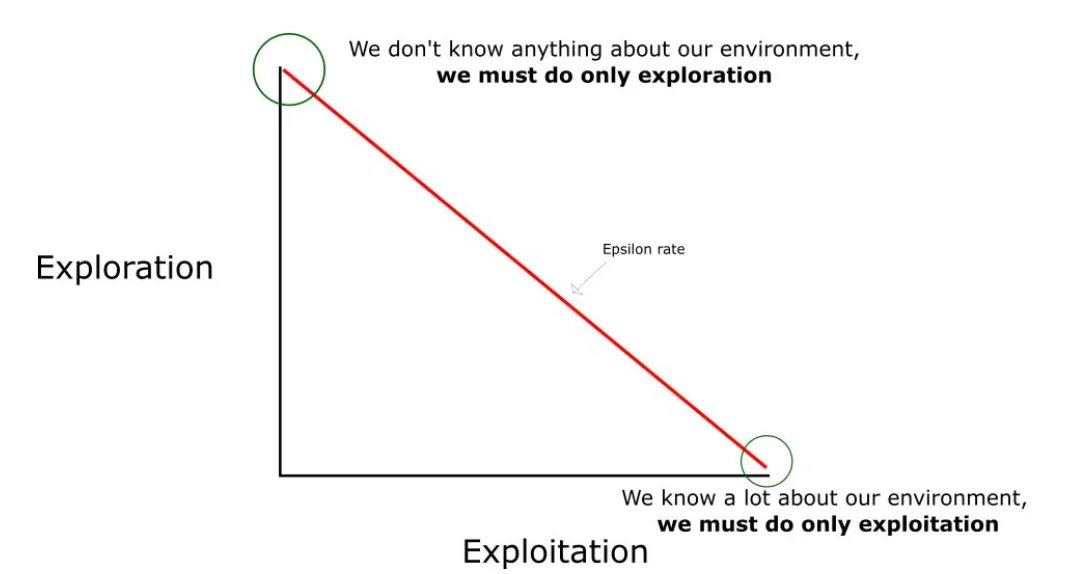
epsilon探索策略
用于权衡探索/利用(exploration/exploitation)
探索:执行随机的动作
利用:
引用自:https://www.jiqizhixin.com/articles/2018-04-17-3
一般情况下刚开始的Q值都默认为0, 也就是Q-TABLE中的任何值都不知道,所以需要通过随机选择动作进行大量的探索。
生成一个随机数,如果这个数大于epsilon,那么就会“利用”Q值进行更新(利用已知知识信息探索动作),否则我们将继续进行随机探索。
可见:epsilon 越大,越倾向于随机探索; epsilon 越小,越倾向于利用已得知识
确定条件下的Q-Learning的收敛性分析
可以证明,https://zhuanlan.zhihu.com/p/365814943 任意的状态动作对任意的状态动作对(s,a),其中s∈A,a∈A,Q^(s,a)将收敛到 Q*(s,a)。其中 Q就是最优策略 π所对应的Q

2. 关于On-policy和Off-policy
在强化学习中,On-policy 和 Off-policy 主要的区别在于智能体学习的过程中,策略的更新和行为的选择是否依赖于同一策略。
- On-policy 就像是一个学生只能根据自己当前的学习方法来学习并改进自己,所采取的学习策略直接影响自己的学习过程。
- Off-policy 就像是一个学生在学习时可以参考别人(老师或其他人的策略),即使自己并没有按照这个策略进行学习,也能从其他人的行为中获得反馈来改进自己的策略。
1. On-policy(策略学习与行为选择一致):
在 On-policy 学习中,智能体在学习过程中,使用同一个策略来选择动作,并且基于这个策略的行为来更新自己的策略。也就是说,智能体的行为和它学习的策略是紧密相关的。这个策略不仅用于决策,还被用来指导更新 Q 值。
类比:
假设你正在学习开车,你决定遵循某个驾驶技巧(比如“慢速启动,平稳加速”),你按照这个方法开车并通过经验调整你的驾驶技巧。你的驾驶技巧(策略)和你实际开车时采取的动作(行为)是相同的,你根据实际开车的表现来逐步改进技巧。
例子:
- SARSA(State-Action-Reward-State-Action)是 On-policy 算法。在 SARSA 中,智能体在每个状态下选择一个动作,然后根据该动作的奖励和下一个状态,继续根据当前策略进行选择。策略的更新是基于智能体自己采取的动作的。
2. Off-policy(策略学习与行为选择不一致):
在 Off-policy 学习中,智能体可以根据一个策略来学习,但它不必按照这个策略来选择动作,也就是说,智能体可能会用不同的策略来选择动作,并且在学习时依赖于另一个(行为)策略的经验来更新它的学习策略。
类比:
现在你还是在学习开车,但是你决定向有经验的老司机请教,尽管你自己还没有完全学会这个技巧。你观察老司机是如何驾驶的,模拟他们的操作(比如“快速启动,紧急刹车”),然后自己尝试通过这些观察来改进你的驾驶技巧。这里,你学习的技巧和你实际开车时采用的方式可以不同。
例子:
- Q-learning 是 Off-policy 算法。在 Q-learning 中,智能体选择一个动作来与环境交互,并根据环境的反馈来更新 Q 值。虽然它使用 ε-贪婪策略(通过随机选择动作来探索环境),但它更新 Q 值时是基于“最优策略”(即选择最大 Q 值的动作)来学习的,不依赖于实际采取的动作。
Q-learning 是 Off-policy:
Q-learning 是一种典型的 Off-policy 算法。它通过更新 Q 函数来找到最优策略,但它在选择动作时并不完全依赖于当前的 Q 函数,而是采用了 ε-贪婪策略,即有时选择随机动作(探索),有时选择 Q 值最大的动作(利用)。因此,Q-learning 中的学习与行为选择是不一致的,也就是 Off-policy。
3. Q-Learning demo for Blackjack in Gymnasium(二十一点)
https://gymnasium.org.cn/introduction/train_agent/
二十一点规则
具体实现
- 训练代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106import gymnasium as gym
from tqdm import tqdm
import matplotlib.pyplot as plt
from BlackjackAgent import BlackjackAgent # 导入 BlackjackAgent 类
import numpy as np
# 设置超参数
learning_rate = 0.01
n_episodes = 100_000
start_epsilon = 1.0
epsilon_decay = start_epsilon / (n_episodes / 2) # 逐步减少探索
final_epsilon = 0.1
# 创建环境
env = gym.make("Blackjack-v1", sab=False)
# 初始化代理
agent = BlackjackAgent(
env=env,
learning_rate=learning_rate,
initial_epsilon=start_epsilon,
epsilon_decay=epsilon_decay,
final_epsilon=final_epsilon,
)
env = gym.wrappers.RecordEpisodeStatistics(env)
# 用于记录奖励和误差
episode_rewards = []
episode_errors = []
# 训练过程
for episode in tqdm(range(n_episodes)):
obs, info = env.reset()
done = False
total_reward = 0
while not done:
action = agent.get_action(obs)
next_obs, reward, terminated, truncated, info = env.step(action)
# 更新代理
agent.update(obs, action, reward, terminated, next_obs)
total_reward += reward
done = terminated or truncated
obs = next_obs
# 记录每回合的奖励和误差
episode_rewards.append(total_reward)
episode_errors.append(np.mean(agent.training_error)) # 记录当前回合的平均误差
# 更新 epsilon
agent.decay_epsilon()
# 训练完成,绘制奖励和误差曲线
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 10))
# 绘制奖励曲线
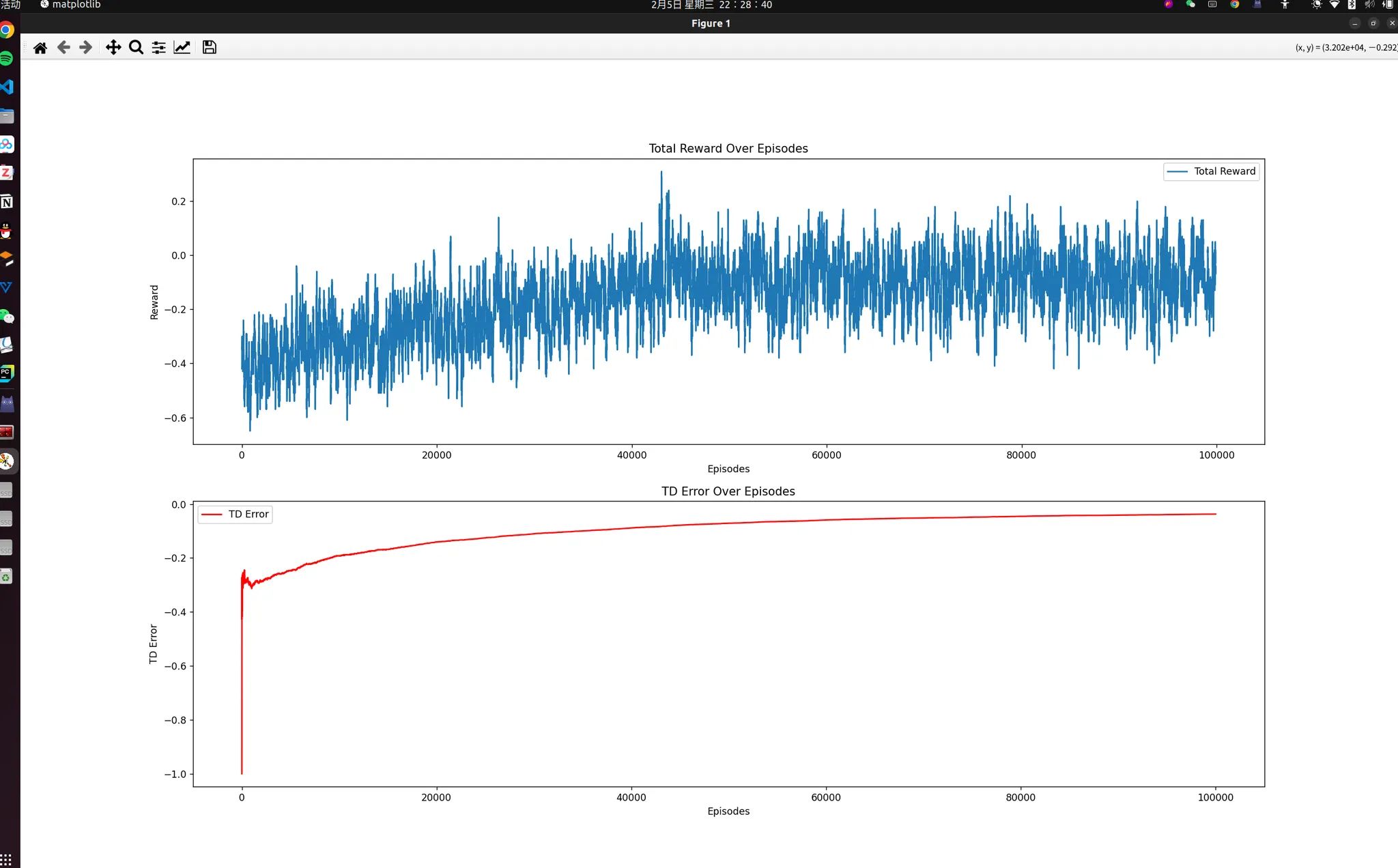
ax1.plot(np.convolve(episode_rewards, np.ones(100)/100, mode='valid'), label="Total Reward")
ax1.set_title("Total Reward Over Episodes")
ax1.set_xlabel("Episodes")
ax1.set_ylabel("Reward")
ax1.legend()
# 绘制 TD 误差曲线
ax2.plot(episode_errors, label="TD Error", color='r')
ax2.set_title("TD Error Over Episodes")
ax2.set_xlabel("Episodes")
ax2.set_ylabel("TD Error")
ax2.legend()
plt.show()
# ================== 方法二:测试智能体性能 ================== #
test_episodes = 1000 # 运行 1000 回合
total_wins = 0
total_games = 0
total_rewards = []
for _ in range(test_episodes):
obs, info = env.reset()
done = False
total_reward = 0
while not done:
action = np.argmax(agent.q_values[obs]) # 选择最优策略
obs, reward, terminated, truncated, info = env.step(action)
total_reward += reward
done = terminated or truncated
total_rewards.append(total_reward)
if total_reward > 0:
total_wins += 1
total_games += 1
win_rate = total_wins / total_games * 100
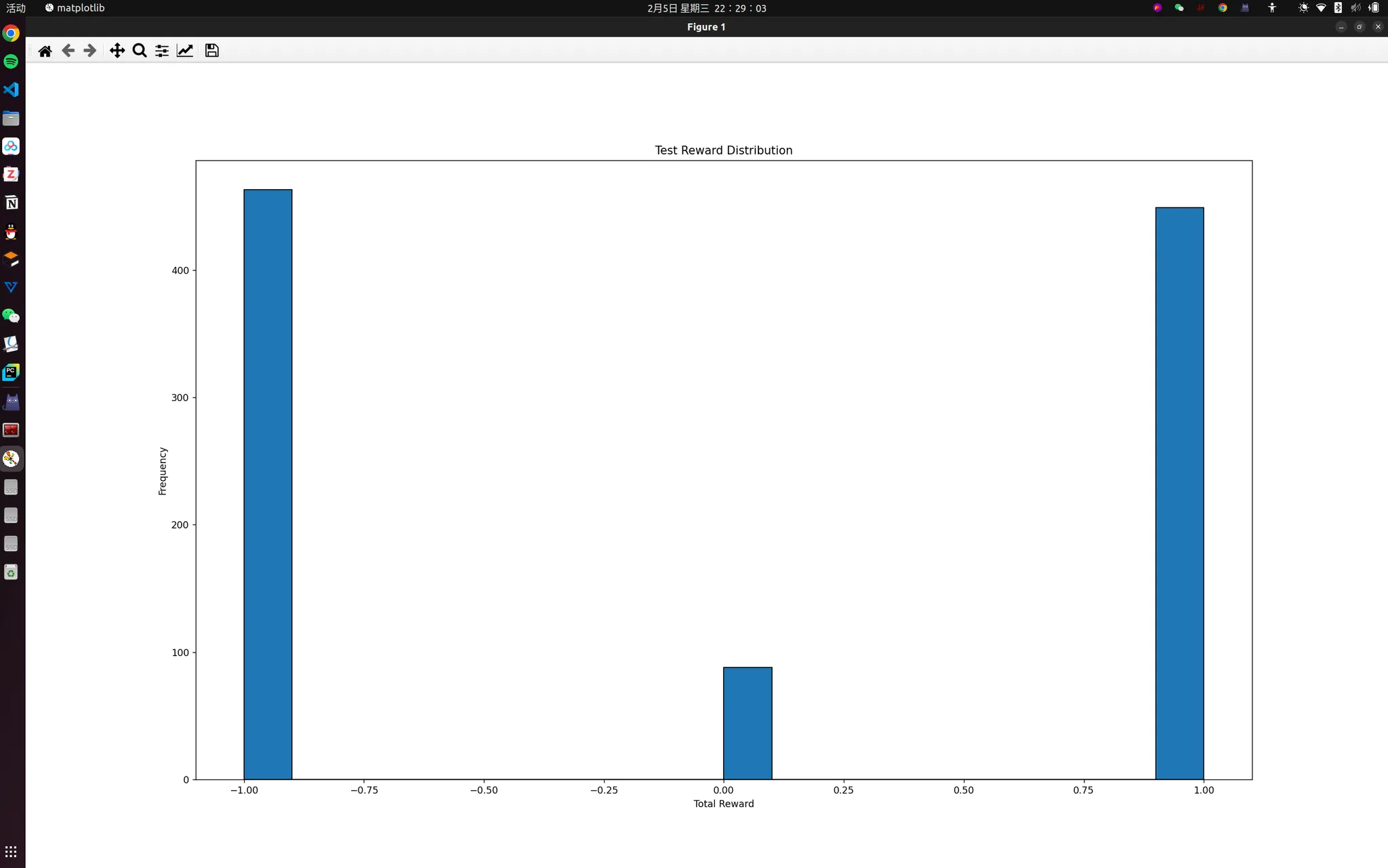
print(f"Win rate over {test_episodes} episodes: {win_rate:.2f}%")
# 绘制测试奖励分布直方图
plt.figure(figsize=(12, 5))
plt.hist(total_rewards, bins=20, edgecolor='black')
plt.xlabel("Total Reward")
plt.ylabel("Frequency")
plt.title("Test Reward Distribution")
plt.show()- agent类代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72# BlackjackAgent.py
from collections import defaultdict
import numpy as np
import gymnasium as gym
class BlackjackAgent:
def __init__(
self,
env: gym.Env,
learning_rate: float,
initial_epsilon: float,
epsilon_decay: float,
final_epsilon: float,
discount_factor: float = 0.95,
):
"""Initialize a Reinforcement Learning agent with an empty dictionary
of state-action values (q_values), a learning rate and an epsilon.
Args:
env: The training environment
learning_rate: The learning rate
initial_epsilon: The initial epsilon value
epsilon_decay: The decay for epsilon
final_epsilon: The final epsilon value
discount_factor: The discount factor for computing the Q-value
"""
self.env = env
self.q_values = defaultdict(lambda: np.zeros(env.action_space.n))
self.lr = learning_rate
self.discount_factor = discount_factor
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
self.training_error = []
def get_action(self, obs: tuple[int, int, bool]) -> int:
"""
Returns the best action with probability (1 - epsilon)
otherwise a random action with probability epsilon to ensure exploration.
"""
# with probability epsilon return a random action to explore the environment
if np.random.random() < self.epsilon:
return self.env.action_space.sample()
# with probability (1 - epsilon) act greedily (exploit)
else:
return int(np.argmax(self.q_values[obs]))
def update(
self,
obs: tuple[int, int, bool],
action: int,
reward: float,
terminated: bool,
next_obs: tuple[int, int, bool],
):
"""Updates the Q-value of an action."""
future_q_value = (not terminated) * np.max(self.q_values[next_obs])
temporal_difference = (
reward + self.discount_factor * future_q_value - self.q_values[obs][action]
)
self.q_values[obs][action] = (
self.q_values[obs][action] + self.lr * temporal_difference
)
self.training_error.append(temporal_difference)
def decay_epsilon(self):
self.epsilon = max(self.final_epsilon, self.epsilon - self.epsilon_decay)测试结果图
https://gymnasium.org.cn/introduction/train_agent/
二十一点规则
具体实现
训练代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106import gymnasium as gym
from tqdm import tqdm
import matplotlib.pyplot as plt
from BlackjackAgent import BlackjackAgent # 导入 BlackjackAgent 类
import numpy as np
# 设置超参数
learning_rate = 0.01
n_episodes = 100_000
start_epsilon = 1.0
epsilon_decay = start_epsilon / (n_episodes / 2) # 逐步减少探索
final_epsilon = 0.1
# 创建环境
env = gym.make("Blackjack-v1", sab=False)
# 初始化代理
agent = BlackjackAgent(
env=env,
learning_rate=learning_rate,
initial_epsilon=start_epsilon,
epsilon_decay=epsilon_decay,
final_epsilon=final_epsilon,
)
env = gym.wrappers.RecordEpisodeStatistics(env)
# 用于记录奖励和误差
episode_rewards = []
episode_errors = []
# 训练过程
for episode in tqdm(range(n_episodes)):
obs, info = env.reset()
done = False
total_reward = 0
while not done:
action = agent.get_action(obs)
next_obs, reward, terminated, truncated, info = env.step(action)
# 更新代理
agent.update(obs, action, reward, terminated, next_obs)
total_reward += reward
done = terminated or truncated
obs = next_obs
# 记录每回合的奖励和误差
episode_rewards.append(total_reward)
episode_errors.append(np.mean(agent.training_error)) # 记录当前回合的平均误差
# 更新 epsilon
agent.decay_epsilon()
# 训练完成,绘制奖励和误差曲线
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 10))
# 绘制奖励曲线
ax1.plot(np.convolve(episode_rewards, np.ones(100)/100, mode='valid'), label="Total Reward")
ax1.set_title("Total Reward Over Episodes")
ax1.set_xlabel("Episodes")
ax1.set_ylabel("Reward")
ax1.legend()
# 绘制 TD 误差曲线
ax2.plot(episode_errors, label="TD Error", color='r')
ax2.set_title("TD Error Over Episodes")
ax2.set_xlabel("Episodes")
ax2.set_ylabel("TD Error")
ax2.legend()
plt.show()
# ================== 方法二:测试智能体性能 ================== #
test_episodes = 1000 # 运行 1000 回合
total_wins = 0
total_games = 0
total_rewards = []
for _ in range(test_episodes):
obs, info = env.reset()
done = False
total_reward = 0
while not done:
action = np.argmax(agent.q_values[obs]) # 选择最优策略
obs, reward, terminated, truncated, info = env.step(action)
total_reward += reward
done = terminated or truncated
total_rewards.append(total_reward)
if total_reward > 0:
total_wins += 1
total_games += 1
win_rate = total_wins / total_games * 100
print(f"Win rate over {test_episodes} episodes: {win_rate:.2f}%")
# 绘制测试奖励分布直方图
plt.figure(figsize=(12, 5))
plt.hist(total_rewards, bins=20, edgecolor='black')
plt.xlabel("Total Reward")
plt.ylabel("Frequency")
plt.title("Test Reward Distribution")
plt.show()agent类代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72# BlackjackAgent.py
from collections import defaultdict
import numpy as np
import gymnasium as gym
class BlackjackAgent:
def __init__(
self,
env: gym.Env,
learning_rate: float,
initial_epsilon: float,
epsilon_decay: float,
final_epsilon: float,
discount_factor: float = 0.95,
):
"""Initialize a Reinforcement Learning agent with an empty dictionary
of state-action values (q_values), a learning rate and an epsilon.
Args:
env: The training environment
learning_rate: The learning rate
initial_epsilon: The initial epsilon value
epsilon_decay: The decay for epsilon
final_epsilon: The final epsilon value
discount_factor: The discount factor for computing the Q-value
"""
self.env = env
self.q_values = defaultdict(lambda: np.zeros(env.action_space.n))
self.lr = learning_rate
self.discount_factor = discount_factor
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
self.training_error = []
def get_action(self, obs: tuple[int, int, bool]) -> int:
"""
Returns the best action with probability (1 - epsilon)
otherwise a random action with probability epsilon to ensure exploration.
"""
# with probability epsilon return a random action to explore the environment
if np.random.random() < self.epsilon:
return self.env.action_space.sample()
# with probability (1 - epsilon) act greedily (exploit)
else:
return int(np.argmax(self.q_values[obs]))
def update(
self,
obs: tuple[int, int, bool],
action: int,
reward: float,
terminated: bool,
next_obs: tuple[int, int, bool],
):
"""Updates the Q-value of an action."""
future_q_value = (not terminated) * np.max(self.q_values[next_obs])
temporal_difference = (
reward + self.discount_factor * future_q_value - self.q_values[obs][action]
)
self.q_values[obs][action] = (
self.q_values[obs][action] + self.lr * temporal_difference
)
self.training_error.append(temporal_difference)
def decay_epsilon(self):
self.epsilon = max(self.final_epsilon, self.epsilon - self.epsilon_decay)测试结果图

- 标题: Q-learning
- 作者: Porcovsky
- 创建于 : 2025-02-07 09:46:33
- 更新于 : 2025-06-12 11:09:59
- 链接: https://pocro.github.io/2025/02/07/Q-learning/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。